Announcing a holiday gift: 🎅SantaCoder - a 1.1B multilingual LM for code that outperforms much larger open-source models on both left-to-right generation and infilling!
Demo: hf.co/spaces/bigcode…
Paper: hf.co/datasets/bigco…
Attribution: hf.co/spaces/bigcode…
A🧵:
Demo: hf.co/spaces/bigcode…
Paper: hf.co/datasets/bigco…
Attribution: hf.co/spaces/bigcode…
A🧵:

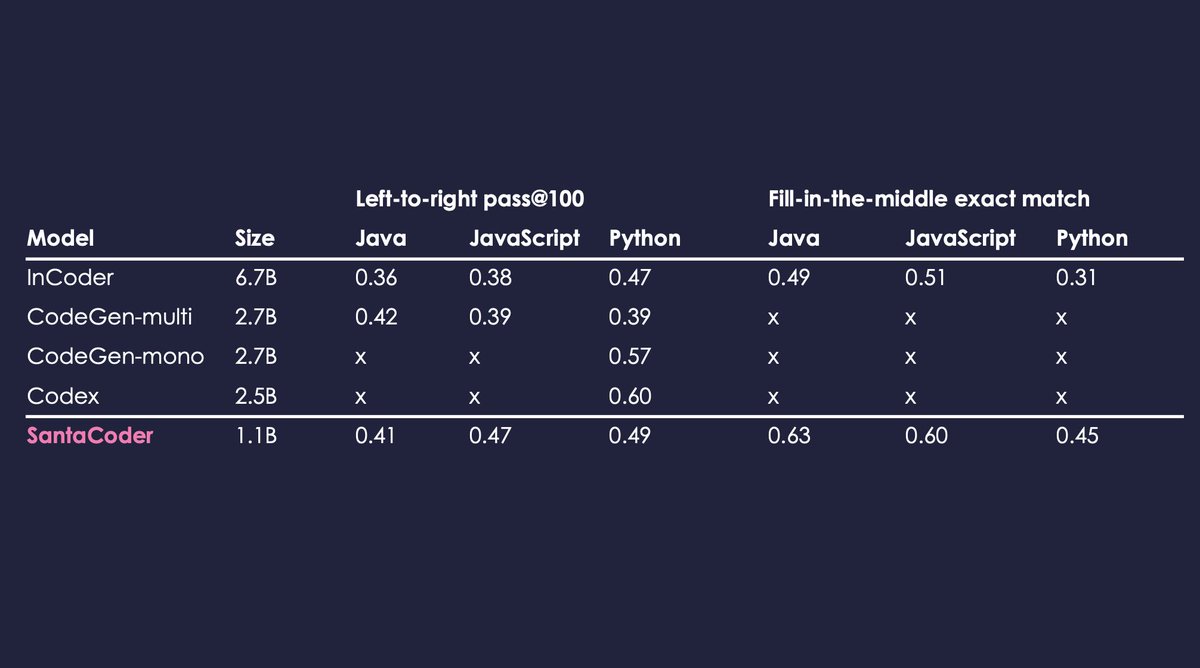
SantaCoder is trained on Python, Java, and JavaScript and outperforms other large multilingual models such as InCoder (6.7B) or CodeGen-multi (2.7B) considerably!
A lot of pieces from a lot of collaborators came together to get to that result:
A lot of pieces from a lot of collaborators came together to get to that result:
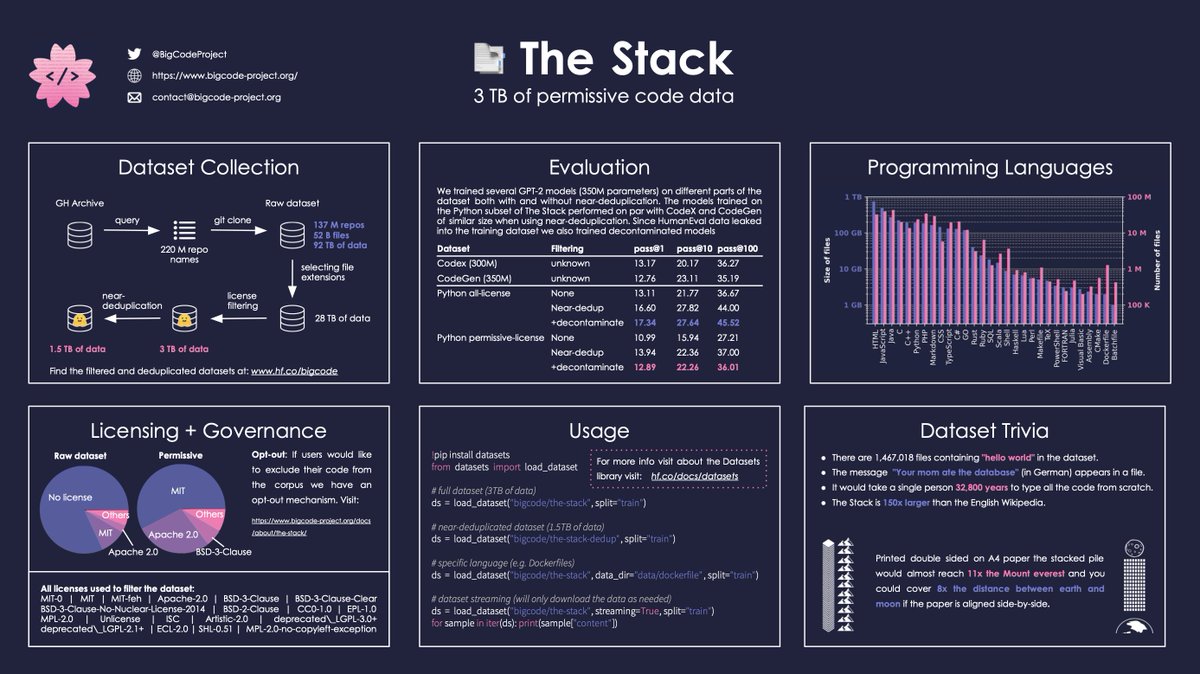
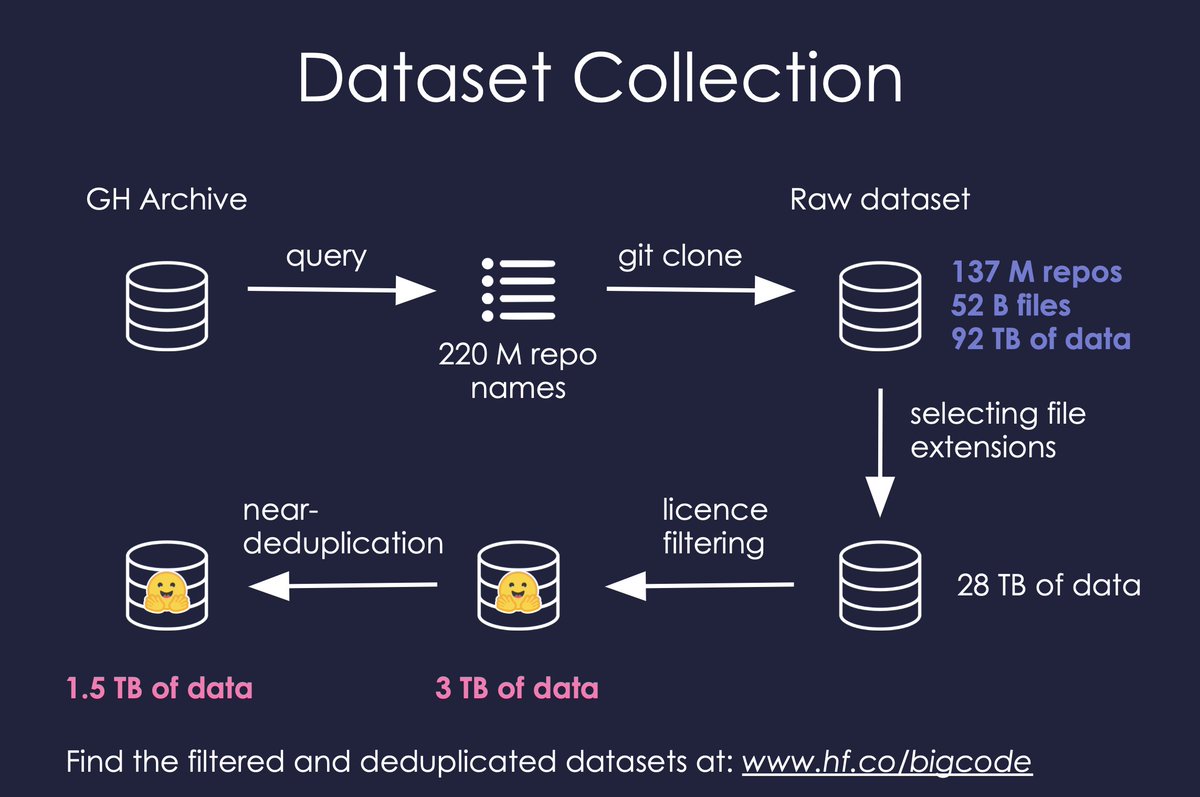
The foundation to train SantaCoder is The Stack (v1.1) dataset. Given the relatively small size of our model (1B parameters) we chose three popular programming languages: Python, Java, and JavaScript.
You can check if your code was used for training here: huggingface.co/spaces/bigcode…
You can check if your code was used for training here: huggingface.co/spaces/bigcode…
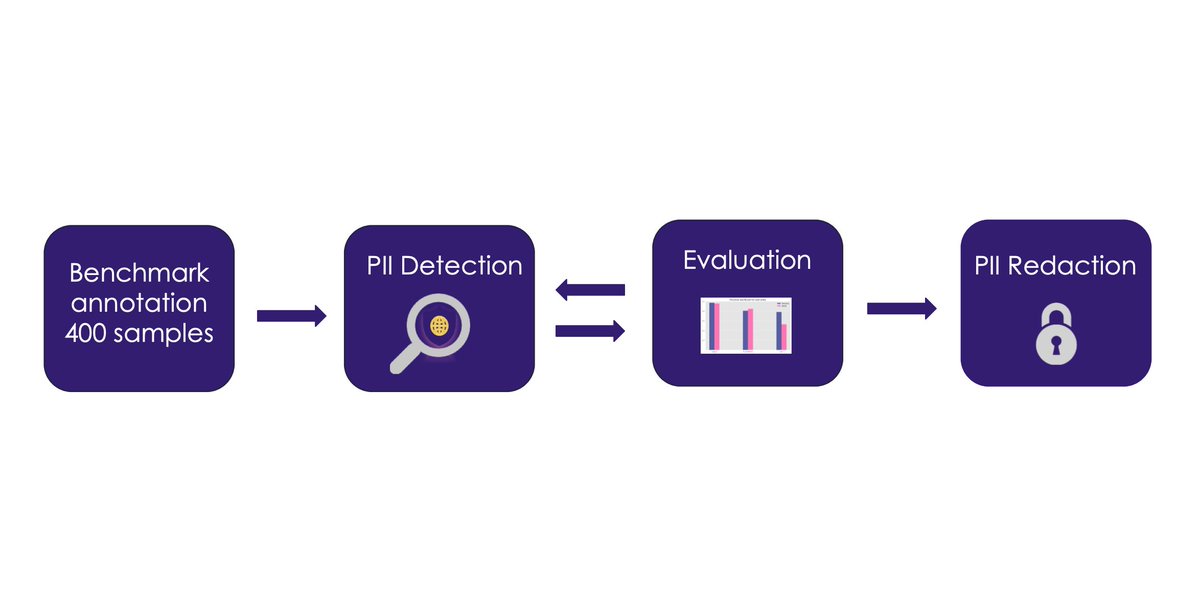
Before training any models we looked into removing sensitive information from code such as email addresses, secret keys and IP addresses. For that purpose we annotated 400 samples and then built and continuously refined RegEx rules to remove the information before training.
In our experiments, we explored two questions:
First, can we use Multi Query Attention (MQA) together with Fill-in-the-middle (FIM) without performance loss?
Secondly, what's the best data filtering procedure for code models?
First, can we use Multi Query Attention (MQA) together with Fill-in-the-middle (FIM) without performance loss?
Secondly, what's the best data filtering procedure for code models?
In Multi Head Attention every head has a set of queries, keys, and values. In MQA, the queries are unique while keys and values are shared. This saves memory and speeds up inference for large batches. We found it had only a minor impact on performance:


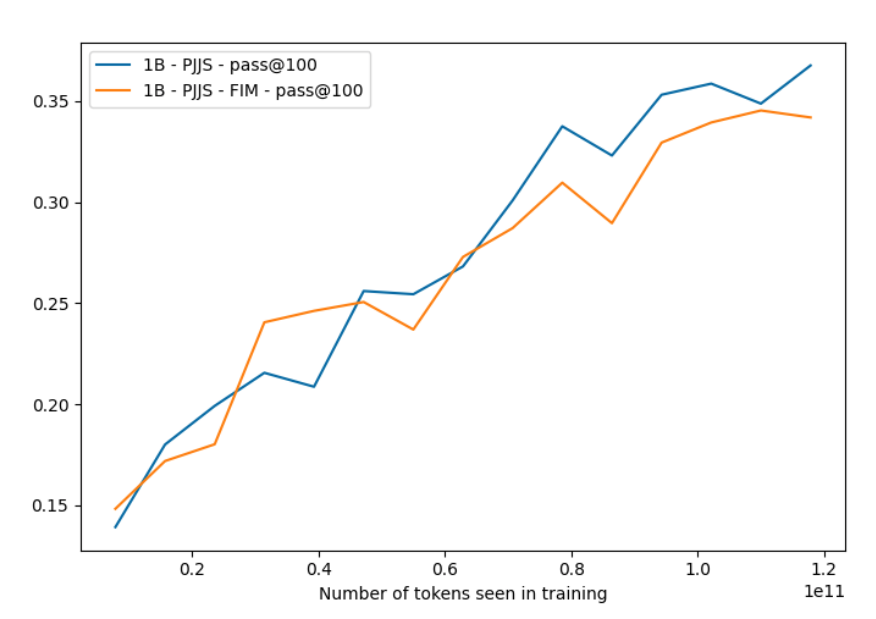
Fill-in-the-Middle is a clever approach where a sequence is reordered such that prefix|middle|suffix becomes prefix|suffix|middle. With that you can use normal left-to-right generation to fill the middle part.
While some claim FIM is for free we found it's rather FIM for cheap:
While some claim FIM is for free we found it's rather FIM for cheap:

In addition to the standard near-deduplication and heuristics pipeline, we ran 4 filtering experiments: GitHub stars, tokenizer fertility, comment-to-code ratio and more near-deduplication.
Filtering for GitHub stars hurts performance while comments and near-dedup help!
Filtering for GitHub stars hurts performance while comments and near-dedup help!

The thorough evaluation was made possible by the evaluation working group. They evaluated on the MultiPL-E benchmark (multilingual HumanEval and MBPP) and CodeXGLUE and extended the code evaluation harness!
github.com/bigcode-projec…
github.com/bigcode-projec…

With these new insights we trained a final model called SantaCoder. We applied both the extra near-deduplication and code-to-comment ratio filters and trained for 600K steps (236B tokens). The result is an efficient (MQA) and flexible (FIM) multilingual model:

We release all models and intermediate checkpoints on the Hugging Face Hub and load the via the revision:
huggingface.co/bigcode/santac…
The compute for these experiments was sponsored by @ServiceNowRSRCH's research cluster.
huggingface.co/bigcode/santac…
The compute for these experiments was sponsored by @ServiceNowRSRCH's research cluster.

The SantaCoder models are licensed under an open & responsible AI license (OpenRAIL). These are AI-specific licenses enabling free use and distribution of the model while setting specific use restrictions (e.g. malware generation). cc @ResponsibleAIL
FAQ: bigcode-project.org/docs/pages/mod…
FAQ: bigcode-project.org/docs/pages/mod…
An important aspect of using these models is that they can copy code from the training data which requires attribution. To help users navigate this we built a search index of the pretraining data.
hf.co/spaces/bigcode…
hf.co/spaces/bigcode…
Finally, we summarized our findings in a technical report with a wonderful group of collaborators:
Paper: hf.co/datasets/bigco…
So what's next? Scaling to larger models and training more languages early next year! 🚀
Paper: hf.co/datasets/bigco…
So what's next? Scaling to larger models and training more languages early next year! 🚀

• • •
Missing some Tweet in this thread? You can try to
force a refresh