
The ultimate achievement to some in the AI industry is creating a system with artificial general intelligence (AGI), or the ability to understand and learn any task that a human can. Long relegated to the domain of science fiction, it’s been suggested that AGI would bring about systems with the ability to reason, plan, learn, represent knowledge and communicate in natural language.
Not every expert is convinced that AGI is a realistic goal — or even possible. But it could be argued that DeepMind, the Alphabet-backed research lab, took a step toward it this week with the release of an AI system called Gato.
Gato is what DeepMind describes as a “general-purpose” system, a system that can be taught to perform many different types of tasks. Researchers at DeepMind trained Gato to complete 604, to be exact, including captioning images, engaging in dialogue, stacking blocks with a real robot arm and playing Atari games.
“Most current AI systems work on a single task or narrow domain at a time. The significance of this work is mainly that one agent with one [model] can do hundreds of very different tasks, including to control a real robot and do basic captioning and chat,” Scott Reed, a researcher scientist at DeepMind and one of the co-creators of Gato, told TechCrunch via email.
Jack Hessel, a research scientist at the Allen Institute for AI, points out that a single AI system that can solve many tasks isn’t new. For example, Google recently began using a system in Google Search called multitask unified model, or MUM, which can handle text, images and videos to perform tasks, from finding interlingual variations in the spelling of a word to relating a search query to an image. But what is potentially newer, here, Hessel says, is the diversity of the tasks that are tackled and the training method.
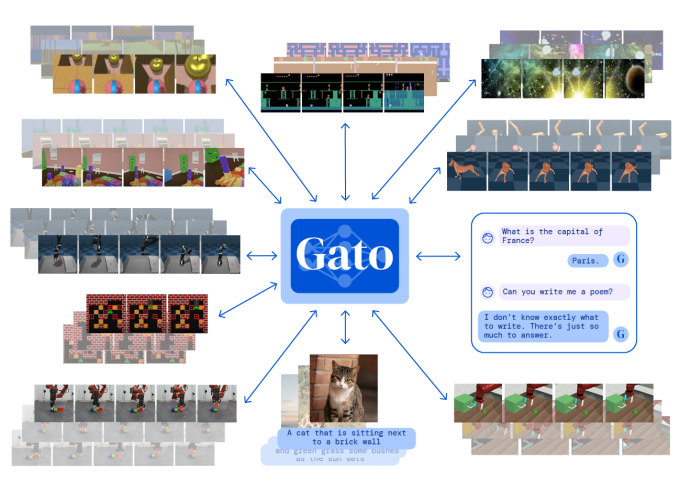
“We’ve seen evidence previously that single models can handle surprisingly diverse sets of inputs,” Hessel told TechCrunch via email. “In my view, the core question when it comes to multitask learning … is whether the tasks complement each other or not. You could envision a more boring case if the model implicitly separates the tasks before solving them, e.g., ‘If I detect task A as an input, I will use subnetwork A. If I instead detect task B, I will use different subnetwork B.’ For that null hypothesis, similar performance could be attained by training A and B separately, which is underwhelming. In contrast, if training A and B jointly leads to improvements for either (or both!), then things are more exciting.”
Like all AI systems, Gato learned by example, ingesting billions of words, images from real-world and simulated environments, button presses, joint torques and more in the form of tokens. These tokens served to represent data in a way Gato could understand, enabling the system to — for example — tease out the mechanics of Breakout, or which combination of words in a sentence might make grammatical sense.
Gato doesn’t necessarily do these tasks well. For example, when chatting with a person, the system often responds with a superficial or factually incorrect reply (e.g. “Marseille” in response to “What is the capital of France?”). In captioning pictures, Gato misgenders people. And the system correctly stacks blocks using a real-world robot only 60% of the time.
But on 450 of the 604 aforementioned tasks, DeepMind claims that Gato performs better than an expert more than half the time.
“If you’re of the mind that we need general [systems], which is a lot of folks in the AI and machine learning area, then [Gato is] a big deal,” Matthew Guzdial, an assistant professor of computing science at the University of Alberta, told TechCrunch via email. “I think people saying it’s a major step towards AGI are overhyping it somewhat, as we’re still not at human intelligence and likely not to get there soon (in my opinion). I’m personally more in the camp of many small models [and systems] being more useful, but there’s definitely benefits to these general models in terms of their performance on tasks outside their training data.”
Curiously, from an architectural standpoint, Gato isn’t dramatically different from many of the AI systems in production today. It shares characteristics in common with OpenAI’s GPT-3 in the sense that it’s a “Transformer.” Dating back to 2017, the Transformer has become the architecture of choice for complex reasoning tasks, demonstrating an aptitude for summarizing documents, generating music, classifying objects in images and analyzing protein sequences.

Perhaps even more remarkably, Gato is orders of magnitude smaller than single-task systems, including GPT-3, in terms of the parameter count. Parameters are the parts of the system learned from training data and essentially define the skill of the system on a problem, such as generating text. Gato has just 1.2 billion, while GPT-3 has more than 170 billion.
DeepMind researchers kept Gato purposefully small so the system could control a robot arm in real time. But they hypothesize that — if scaled up — Gato could tackle any “task, behavior, and embodiment of interest.”
Assuming this turns out to be the case, several other hurdles would have to be overcome to make Gato superior in specific tasks to cutting-edge single-task systems, like Gato’s inability to learn continuously. Like most Transformer-based systems, Gato’s knowledge of the world is grounded in the training data and remains static. If you ask Gato a date-sensitive question, like the current president of the U.S., chances are it would respond incorrectly.
The Transformer — and Gato, by extension — has another limitation in its context window, or the amount of information the system can “remember” in the context of a given task. Even the best Transformer-based language models can’t write a lengthy essay, much less a book, without failing to remember key details and thus losing track of the plot. The forgetting happens in any task, whether writing or controlling a robot, which is why some experts have called it the “Achilles’ heel” of machine learning.
For these reasons and others, Mike Cook, a member of the Knives & Paintbrushes research collective, cautions against assuming Gato is a path to truly general-purpose AI.
“I think the result is open to misinterpretation, somewhat. It sounds exciting that the AI is able to do all of these tasks that sound very different, because to us it sounds like writing text is very different to controlling a robot. But in reality this isn’t all too different from GPT-3 understanding the difference between ordinary English text and Python code,” Cook told TechCrunch via email. “Gato receives specific training data about these tasks, just like any other AI of its type, and it learns how patterns in the data relate to one another, including learning to associate certain kinds of inputs with certain kinds of outputs. This isn’t to say this is easy, but to the outside observer this might sound like the AI can also make a cup of tea or easily learn another ten or fifty other tasks, and it can’t do that. We know that current approaches to large-scale modelling can let it learn multiple tasks at once. I think it’s a nice bit of work, but it doesn’t strike me as a major stepping stone on the path to anything.”






























Comment